
Gaussian Processes from the Ground Up!
As a researcher, I have the habit of learning new and interesting things. Most times these things turn out to become very useful one way or the other. Recently, I found myself in this rabbit hole of Gaussian processes.
A common applied statistics task involves building regression models to characterize non-linear relationships between variables. It is possible to fit such models by assuming a particular non-linear functional form, such as a sinusoidal, exponential, or polynomial function, to describe one variable’s response to the variation in another. Unless this relationship is obvious from the outset, however, it involves possibly extensive model selection procedures to ensure the most appropriate model is retained.
Alternatively, a non-parametric approach can be adopted by defining a set of knots across the variable space and use a spline or kernel regression to describe arbitrary non-linear relationships. However, knot layout procedures are somewhat ad hoc and can also involve variable selection.
A third alternative is to adopt a Bayesian non-parametric strategy, and directly model the unknown underlying function. For this, we can employ Gaussian process models.
Gaussian Processes
Gaussian process is essentially an handy tool for Bayesian inferences on real valued variables. A Gaussian process is a powerful model that can be used to represent a distribution over functions. While most modern machine learning techniques tend to parametise functions and then model these parameters, Gaussian processes are non-parametric models that model the functions directly.
Bayesian Statistics
Many people who have taken a statistics course may not have had a course in Bayesian statistics. Most introductory statistics courses, particularly for non-statisticians like myself, still do not cover Bayesian methods at all, except perhaps to derive Bayes’ formula as a trivial rearrangement of the definition of conditional probability. Even today, Bayesian courses are typically tacked onto the curriculum, rather than being integrated into the program.
In fact, Bayesian statistics is not just a particular method, or even a class of methods; it is an entirely different paradigm for doing statistical analysis.
Practical methods for making inferences from data using probability models for quantities we observe and about which we wish to learn. – Gelman et al. 2013
A Bayesian model is described by parameters, uncertainty in those parameters is described using probability distributions.
All conclusions from Bayesian statistical procedures are stated in terms of probability statements

As a toy example, a child has a prior belief of how a sheep will look like. Later after taking a trip to a countryside with the parents, the parents point at a sheep to the child and say look there is a sheep over there. The child sees the sheep and gets a label. At this point, the child will update his prior belief based on the actual picture of the sheep. The child then combines the initial belief with the actual picture to get a new belief of what a sheep looks like.
In Bayesian inference, the initial belief of the child of what a sheep may look like is called the prior. The updated belief after seeing the actual picture is called the likelihood The child then combines the prior and the likelihood using Bayes’ rule to obtain the posterior.
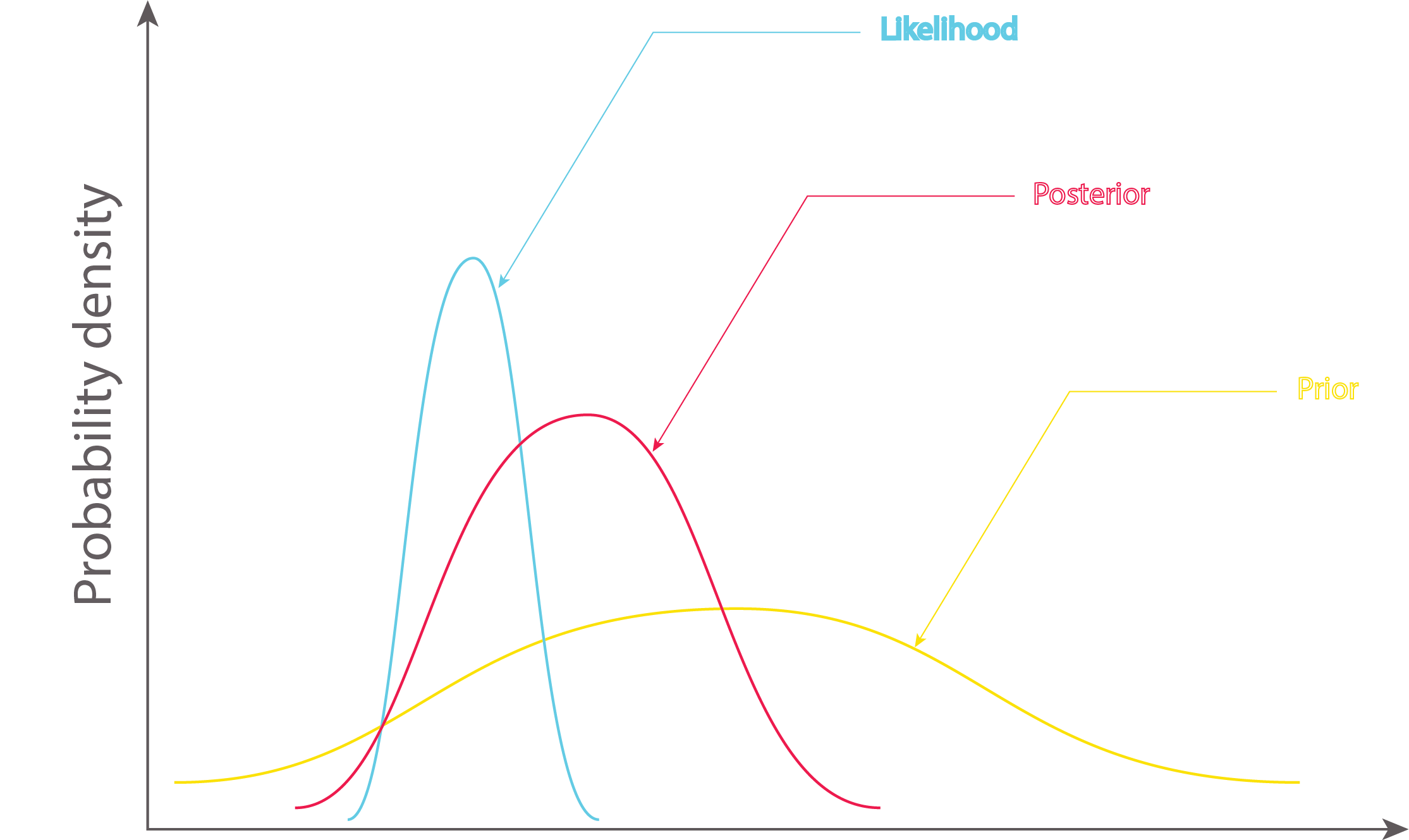
Posterior distribution which is also a Gaussian gives us more confident about our belief and it’s calculated using Bayes’ Formula as shown.

The equation expresses how our belief about the value of \(\theta\), as expressed by the prior distribution \(P(\theta)\) is reallocated following the observation of the data \(y\), as expressed by the posterior distribution.
The denominator \(P(y)\) cannot be calculated directly, and is actually the expression in the numerator, integrated over all \(\theta\):
The intractability of this integral is one of the factors that has contributed to the under-utilization of Bayesian methods by statisticians.
Since we are usually unable to calculate the denominator, numerical approximations are typically applied to estimate the posterior distribution. We will get to the maths of Gaussian processes later in this post, but for now let us get the intuition behind Gaussian processes.
Let us say we intend to carry out the measurement of temperature over time using a temperature sensor. The measurements will look similar to what we have in the graph below.
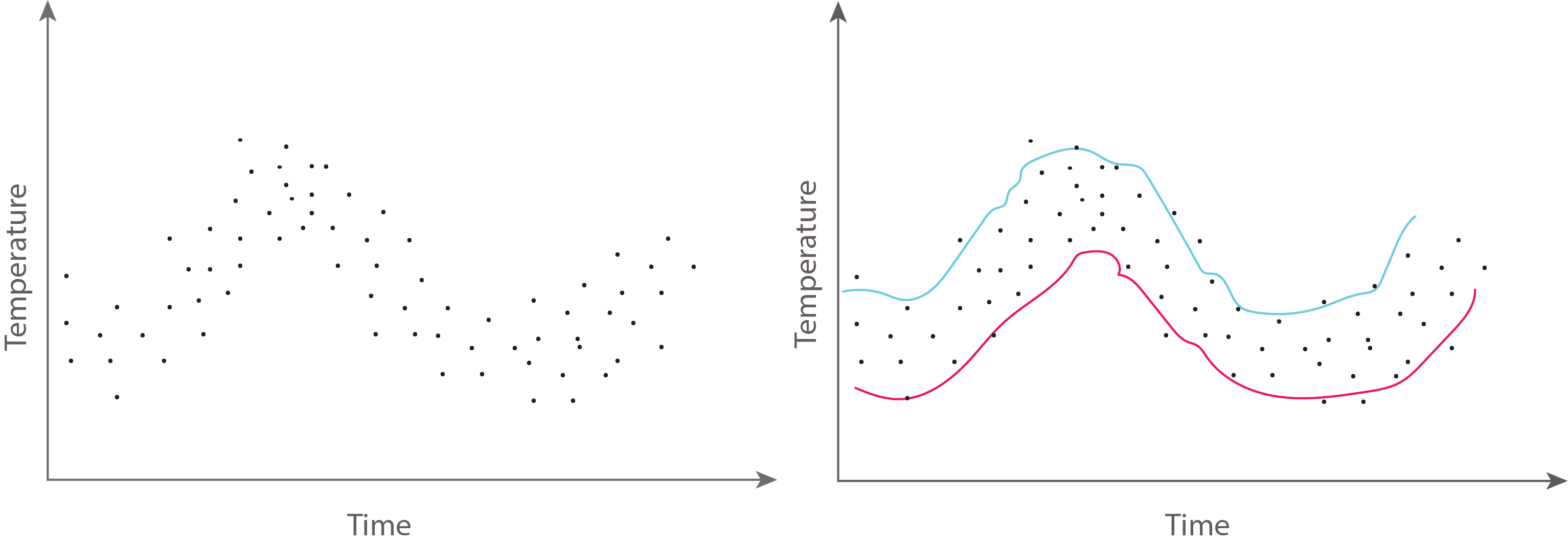
The natural thing we may want to do next is to know what the temperature would be be at a particular time in the future. Normally, when we want to measure the temperature, we fit in different dimensions of Gaussian processes. But rather than going through those individual Gaussian processes, we represent them as a function.
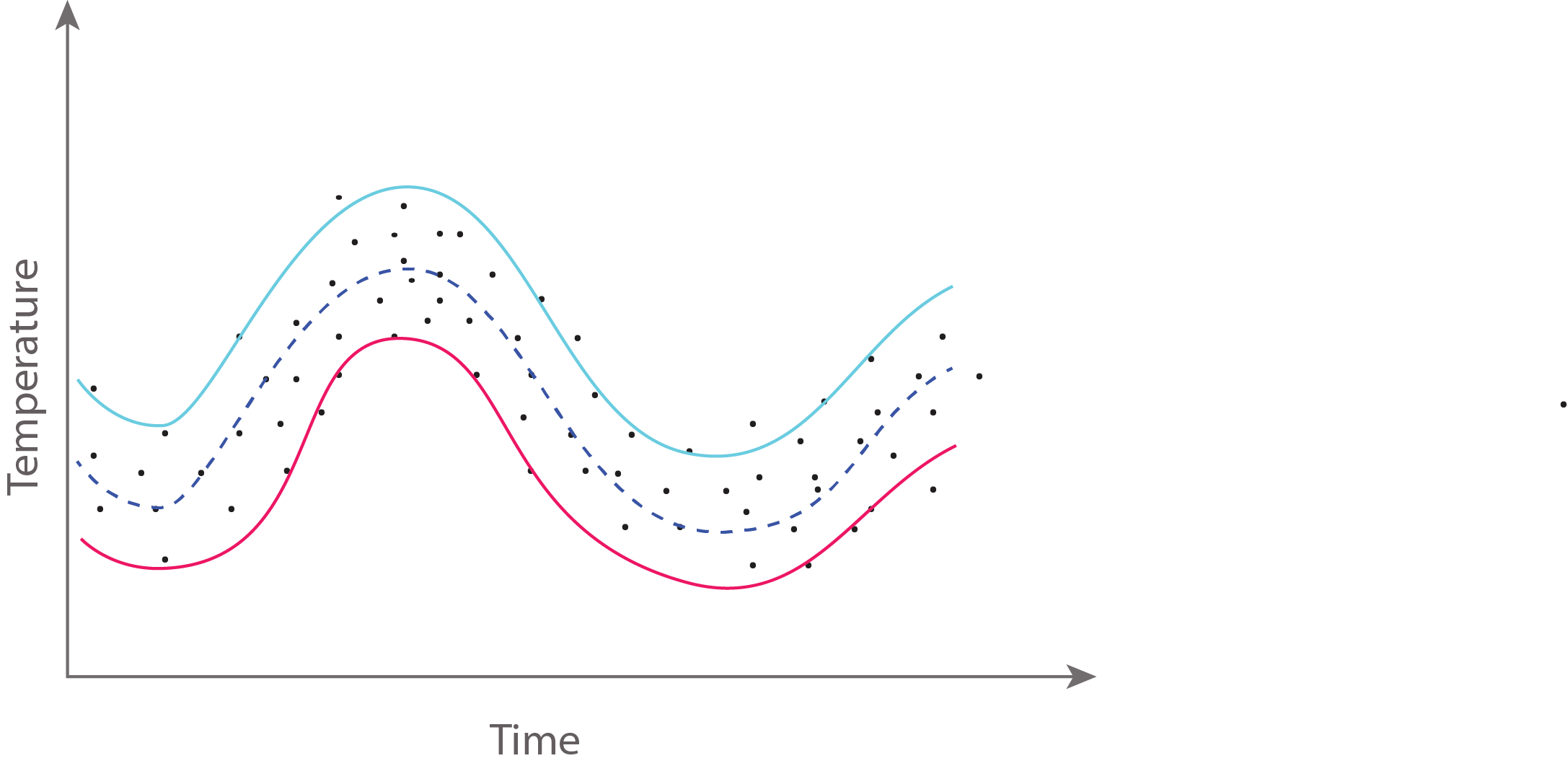
The way we are now going to represent the prior distribution is the mean which is the dash blue line at the centre of the of the function. The envelopes around it are two standard deviations which give us some degree of confidence in our measurements.
Modeling Functions with Gaussians
The major idea behind Gaussian processes is that a function can be modeled using an infinite dimensional multivariate Gaussian distribution. In other words, every point in the input space is associated with a random variable and the joint distribution of these is modeled as a multivariate Gaussian.
Given is jointly Gaussian with parameters
First, the marginal distribution of any subset of elements from a multivariate normal distribution is also normal:
Also, conditional distributions of a subset of a multivariate normal distribution (conditional on the remaining elements) are normal too:
where
A Gaussian process generalizes the multivariate normal to infinite dimension. It is defined as an infinite collection of random variables, any finite subset of which have a Gaussian distribution. Thus, the marginalization property is explicit in its definition. Another way of thinking about an infinite vector is as a function. When we write a function that takes continuous values as inputs, we are essentially specifying an infinte vector that only returns values (indexed by the inputs) when the function is called upon to do so. By the same token, this notion of an infinite-dimensional Gaussian as a function allows us to work with them computationally: we are never required to store all the elements of the Gaussian process, only to calculate them on demand.
So, we can describe a Gaussian process as a disribution over functions. Just as a multivariate normal distribution is completely specified by a mean vector and covariance matrix, a GP is fully specified by a mean function and a covariance function:
It is the marginalization property that makes working with a Gaussian process feasible: we can marginalize over the infinitely-many variables that we are not interested in, or have not observed.
For example, one specification of a GP might be as follows:
here, the covariance function is a squared exponential, for which values of and that are close together result in values of closer to 1 and those that are far apart return values closer to zero.
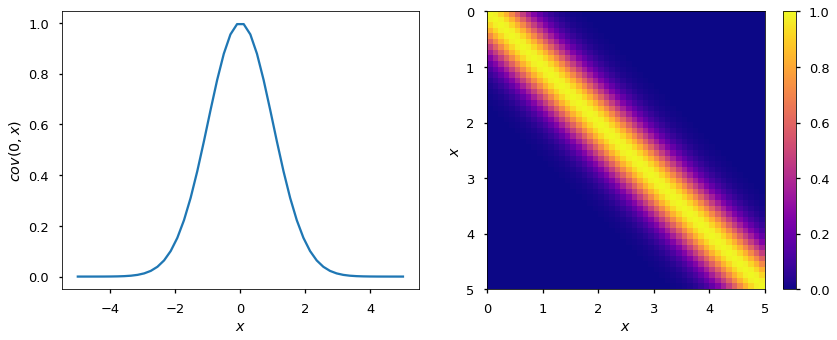
It may seem odd to simply adopt the zero function to represent the mean function of the Gaussian process – surely we can do better than that! It turns out that most of the learning in the GP involves the covariance function and its parameters, so very little is gained in specifying a complicated mean function.
For a finite number of points, the GP becomes a multivariate normal, with the mean and covariance as the mean functon and covariance function evaluated at those points.
For example, consider just two points from a squared exponential covariance function with parameters , sampled at locations and .
Let’s consider a value of -1 sampled from . According to our model, there is a dependence regarding where will be located, governed by the covariance of the two variables.
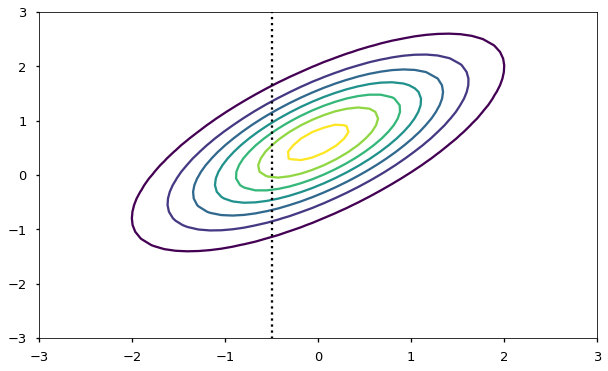
We can apply the normal distribution of from above to see how is constrained:

Notice that if we change the covariance function (either the form or the parameterization), we will change the dependence among points separated by a given distance. We will look at alternate forms of the covariance function a little later on.
Sampling from a Gaussian Process Prior
To make this notion of a “distribution over functions” more concrete, let’s quickly demonstrate how we obtain realizations from a Gaussian process, which result in an evaluation of a function over a set of points. All we will do here is sample from the prior Gaussian process, so before any data have been introduced. What we need first is our covariance function, which will be the squared exponential, and a function to evaluate the covariance at given points (resulting in a covariance matrix).
We are going generate realizations sequentially, point by point, using the lovely conditioning property of mutlivariate Gaussian distributions. Here is that conditional:
And this is the function that implements it:
def conditional(x_new, x, y, params):
B = exponential_cov(x_new, x, params)
C = exponential_cov(x, x, params)
A = exponential_cov(x_new, x_new, params)
mu = np.linalg.inv(C).dot(B.T).T.dot(y)
sigma = A - B.dot(np.linalg.inv(C).dot(B.T))
return(mu.squeeze(), sigma.squeeze())
We will start with a Gaussian process prior with hyperparameters . We will also assume a zero function as the mean, so we can plot a band that represents one standard deviation from the mean.

Let’s select an arbitrary starting point to sample, say . Since there are no prevous points, we can sample from an unconditional Gaussian:
We can now update our confidence band, given the point that we just sampled, using the covariance function to generate new point-wise intervals, conditional on the value .
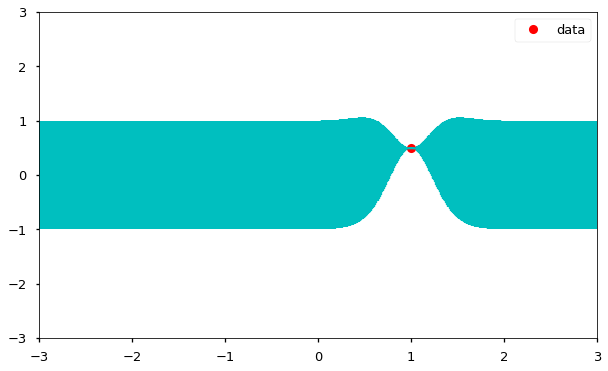
From here we can see that the sample point which is the prior was refined to a posterior distribution just like in the case with the child. It shows that the function is no longer flat but rather close to the datapoint/sample point. We can also see that around the datapoint we sampled, we now have an increased confidence.
As we go through this process and get more and more data, we are scribing out a smooth regression function and we are getting more confident about the envelopes around it. Intuitively, that is a Gaussian Process.
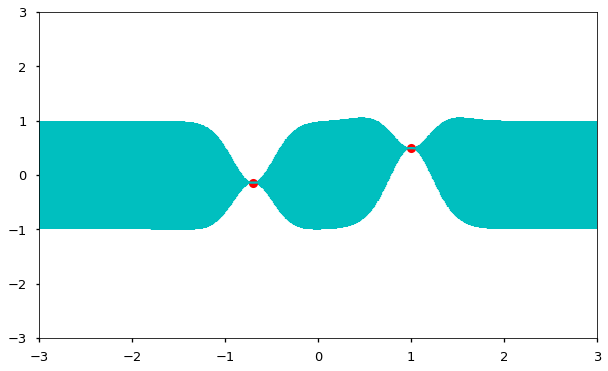
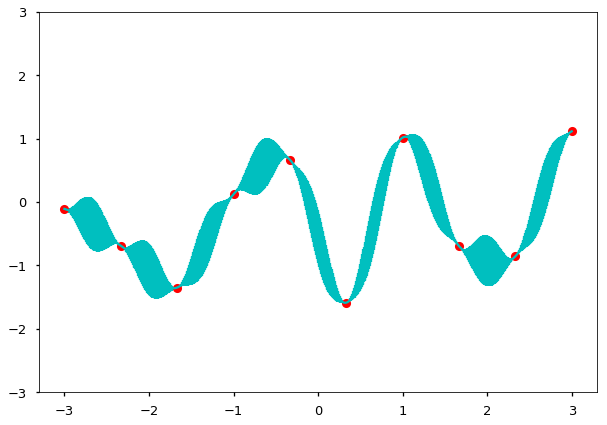
Of course, sampling sequentially is just a heuristic to demonstrate how the covariance structure works. We can just as easily sample several points at once:
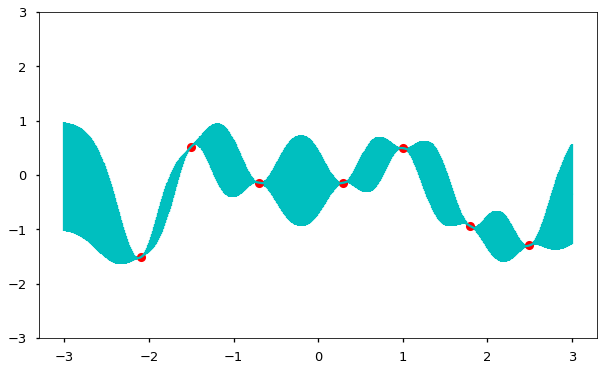
So as the density of points becomes high, the result will be one realization (function) from the prior GP.
This example, of course, is trivial because it is simply a random function drawn from the prior. What we are really interested in is learning about an underlying function from information residing in our data. In a parametric setting, we either specify a likelihood, which we then maximize with respect to the parameters, of a full probability model, for which we calculate the posterior in a Bayesian context. Though the integrals associated with posterior distributions are typically intractable for parametric models, they do not pose a problem with Gaussian processes.
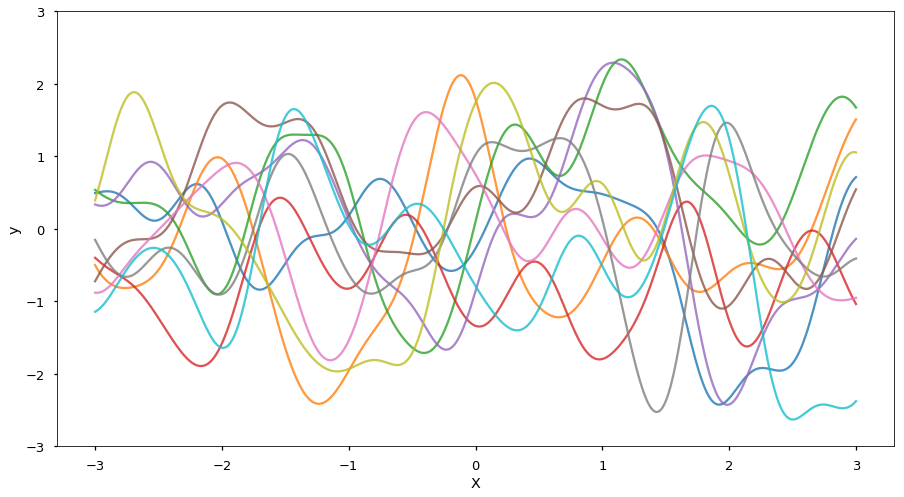
Here is a sample of 10 realizations, predicted over a denser set of x-values:
While univariate Gaussians are distributions over real valued variables, multivariate Gaussians are pairs or finite numbers of distributions over real valued variables, Gaussina processes are functions (infinite number of distibutions over real valued variables. This in general drives us to a notion called regression.
Regressions are quite good for denoising and smoothing. They do not follow every noise in the data. They are also good at predicting and forecasting. For example, we might be interested and want to know what our temperature would be at a particular time in the future. However, regression sometimes have what is called danger of parametric models. For example, trying to fit a quadractic model to a data may lead to the model missing out some important features. There are also dangers of overfitting and underfitting. These are the areas Gaussian processes really shine because they take care of these issues very well.
A Gaussian process is fully specified by its mean and covariance function. Once these are chosen, they are manipulated using probability rules to obtain inference and prediction.
The mean and covariance functions will be the focus of my next post.
The Python codes used in producing these plots are found in my Github
I will like to hear your thoughts on this and also appreciate any feedback.
Leave a Comment