

Web Scraping and Automated Job Search in Python
On my previous post A reflection on my PhD experience I stated that while waiting for my viva, I’m getting ready to start another phase of my career. I’m looking for a role as a machine learning researcher or a data scientist.
As someone who is very passionate about machine learning and data science and would want to make a difference, I would like to work for a company that would avail me the opportunity to work with an incredible group of smart and motivated people in tackling difficult problems. However, getting such role is not easy and does not come cheap. It requires looking out and applying for specific role that I think is best fit for my skillsets.
In this post, instead of the conventional job search, I would describe how I’m going to build an automated web scraper to collect and parse job posting information and then send them as email to me everyday with the various links that match my skillset.
For this fun project, I’ll be focusing on Indeed a major job aggregator site that updates multiple times daily with new job postings and it is one of the top stops in many people’s job search.
Like I said, instead of going through the conventional job search way, by going through every single listing trying to figure out if a particular job post is the best fit for my skillset, I’m going to automate the process by creating a web scraping pipeline.
- Explore the indeed site for recent job listing relevant to me
- Evaluate each one of them and identify the ones that are relevant to my skillset
- Email me with links everyday the results.
I will be building this tool using a package called BeautifulSoup in Python. I’ll be using different standalone functions in building the above listed pipeline.
Exploring a job search in Indeed
First I would like to know if a particular job listing is relevant to my skillset. I can achieve this by going through the job description to know if I am a good match. I would like to see some required skills Python, Data science, machine learning and research. With this simple step, I can write a program that can explore and evaluate that for me. The program can tell me the number of times these key words appear in the description.
Let’s start by pulling a single page, and working out the program to extract each piece of information we want:
#Import the relevant packages and libraries
import re #re stands for regular expressions
import bs4 #bs4 stands for BeautifulSoup
import time #This is very relavant so that we don't overwhemlme the server
import requests
import smtplib
#We define the function explore_job that does the extraction and throws an exception when there is an error
def explore_job(url):
try:
job_html = requests.request('GET', url, timeout = 10)
except:
return 0
#specifying a desired format of “page” using the lxml parser
#this allows python to read the various components of the page, rather than treating it as one long string.
job_soup = bs4.BeautifulSoup(job_html.content, 'lxml')
soup_body = job_soup('body')[0]
#Counting the number of times these keywords appear in the description
python_count = soup_body.text.count('Python') + soup_body.text.count('python')
ds_count = soup_body.text.count('Data Science') + soup_body.text.count('data science')
ml_count = soup_body.text.count('Machine Learning') + soup_body.text.count('machine learning')
research_count = soup_body.text.count('Research') + soup_body.text.count('research')
skill_count = python_count + ds_count + ml_count + research_count
print ('ML count: {0}, Python count: {1}, DS count: {2}, Research count: {3}'.format(ml_count, python_count, ds_count, research_count))
return skill_count
Let us explore and evaluate a sample job post from indeed Data Scientist role in the UK
explore_job('https://www.indeed.co.uk/jobs?q=data+scientist&l=United+Kingdom')
ML count: 7, Python count: 0, DS count: 5, Research count: 4
16
BOOM! We got some keywords that match our skillset. This shows that our explore function is working perfectly.
Now that we have got our explore function working, we will also like to extract other relevant information from a job posting like the title, company name, and the date posted.
#Here we define a new function that extract the relevant information from the link
def extract_job_info(base_url):
response = requests.get(base_url)
soup = bs4.BeautifulSoup(response.content, 'lxml')
#Extracting specific attribute from the job listing
tags = soup.find_all('div', {'data-tn-component' : "organicJob"})
companies_list = [x.span.text for x in tags]
attrs_list = [x.h2.a.attrs for x in tags]
dates = [x.find_all('span', {'class':'date'}) for x in tags]
# update attributes dictionaries with company name and date posted
[attrs_list[i].update({'company': companies_list[i].strip()}) for i, x in enumerate(attrs_list)]
[attrs_list[i].update({'date posted': dates[i][0].text.strip()}) for i, x in enumerate(attrs_list)]
return attrs_list
extract_job_info('https://www.indeed.co.uk/jobs?q=machine+learning&l=United+Kingdom&sort=date')
[{'class': ['turnstileLink'],
'company': 'Amazon',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=0e368de1c08b5a4e&fccid=fe2d21eef233e94a',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[0],true,0);',
'onmousedown': 'return rclk(this,jobmap[0],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Data Scientist Analytics'},
{'class': ['turnstileLink'],
'company': 'Dyson',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=b33762682332d318&fccid=366382f52796fce2',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[1],true,0);',
'onmousedown': 'return rclk(this,jobmap[1],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Graduate Data Scientist 2018'},
{'class': ['turnstileLink'],
'company': 'Amazon',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=37e32588a52e6ffe&fccid=fe2d21eef233e94a',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[2],true,0);',
'onmousedown': 'return rclk(this,jobmap[2],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Software Development Engineer'},
{'class': ['turnstileLink'],
'company': 'Amazon',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=f8ebe3d424b3b0b4&fccid=fe2d21eef233e94a',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[3],true,0);',
'onmousedown': 'return rclk(this,jobmap[3],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Knowledge Engineer (Alexa)'},
{'class': ['turnstileLink'],
'company': 'Costello & Reyes Limited',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=79d80b892dd86ff2&fccid=63ff64eb3db45a69',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[4],true,1);',
'onmousedown': 'return rclk(this,jobmap[4],1);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Data Scientist'},
{'class': ['turnstileLink'],
'company': 'Oliver Bernard',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=b9164bda760cf8b8&fccid=370f24fdcffdfafd',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[5],true,1);',
'onmousedown': 'return rclk(this,jobmap[5],1);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Data Scientist'},
{'class': ['turnstileLink'],
'company': 'Time etc Limited',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/company/Time-etc-Limited/jobs/Onboarding-Assistant-99ab7961474dd43a?fccid=937f18048530601d',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[6],true,1);',
'onmousedown': 'return rclk(this,jobmap[6],1);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Onboarding Assistant'},
{'class': ['turnstileLink'],
'company': 'University of Edinburgh',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=eeffd16ed4cfb697&fccid=16c071074ab13fe5',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[7],true,1);',
'onmousedown': 'return rclk(this,jobmap[7],1);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Research Assistant in Surgical Informatics'},
{'class': ['turnstileLink'],
'company': 'InterQuest Group',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=b2bab32b0616c828&fccid=fc28cf1816ce0889',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[8],true,0);',
'onmousedown': 'return rclk(this,jobmap[8],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Data Scientist'},
{'class': ['turnstileLink'],
'company': 'Aimia',
'data-tn-element': 'jobTitle',
'date posted': 'Just posted',
'href': '/rc/clk?jk=92b52618e0e8767d&fccid=0020889bfe35c4aa',
'onclick': 'setRefineByCookie([]); return rclk(this,jobmap[9],true,0);',
'onmousedown': 'return rclk(this,jobmap[9],0);',
'rel': ['noopener', 'nofollow'],
'target': '_blank',
'title': 'Senior Analyst'}]
Good job boy! You can see we got some pretty good information in there. You can see the title, company name, link, and the date posted. Right, we are on the right tract, let’s move on.
Apart from looking at job titles alone, I might also be interested in looking for a position in some specific companies that I love, admire and have a dream of working with at some point in my career. They are called the BIG FIVE! Amazon, Apple, Microsoft, Google and Facebook.
dream_companies = ['amazon', 'apple', 'microsoft', 'google', 'facebook']
#This function loops through the indeed side and looks for the recently posted ML jobs
def get_new_ml_jobs(days_ago_limit = 1, starting_page = 0, pages_limit = 10, old_jobs_limit = 5,
location = 'United Kingdom', query = 'machine learning'):
query_formatted = re.sub(' ', '+', query)
location_formatted = re.sub(' ', '+', location)
indeed_url = 'http://www.indeed.co.uk/jobs?q={0}&l={1}&sort=date&start='.format(query_formatted, location_formatted)
old_jobs_counter = 0
new_jobs_list = []
for i in range(starting_page, starting_page + pages_limit):
if old_jobs_counter >= old_jobs_limit:
break
print ('URL: {0}'.format(indeed_url + str(i*10)), '\n')
# extract job data from Indeed page
attrs_list = extract_job_info(indeed_url + str(i*10))
# loop through each job, breaking out if we're past the old jobs limit
for j in range(0, len(attrs_list)-1):
if old_jobs_counter >= old_jobs_limit:
break
href = attrs_list[j]['href']
title = attrs_list[j]['title']
company = attrs_list[j]['company']
date_posted = attrs_list[j]['date posted']
# if posting date is beyond the limit, add to the counter and skip
try:
if int(date_posted[0]) >= days_ago_limit:
print ('Adding to old_jobs_counter.')
old_jobs_counter += 1
continue
except:
pass
print ('{0}, {1}, {2}'.format(repr(company), repr(title), repr(date_posted)))
# Explore and evaluate the job
exploration = explore_job('http://indeed.co.uk' + href)
if exploration >= 1 or company.lower() in dream_companies:
new_jobs_list.append('{0}, {1}, {2}'.format(company, title, 'http://indeed.co.uk' + href))
#This is vital because it allows the page to completly before the extraction and listing
print ('\n')
time.sleep(15)
new_jobs_string = '\n\n'.join(new_jobs_list)
return new_jobs_string
def get_new_ds_jobs(days_ago_limit = 1, starting_page = 0, pages_limit = 10, old_jobs_limit = 5,
location = 'United Kingdom', query = 'data scientist'):
query_formatted = re.sub(' ', '+', query)
location_formatted = re.sub(' ', '+', location)
indeed_url = 'http://www.indeed.co.uk/jobs?q={0}&l={1}&sort=date&start='.format(query_formatted, location_formatted)
old_jobs_counter = 0
new_jobs_list = []
for i in range(starting_page, starting_page + pages_limit):
if old_jobs_counter >= old_jobs_limit:
break
print ('URL: {0}'.format(indeed_url + str(i*10)), '\n')
# extract job data from Indeed page
attrs_list = extract_job_info(indeed_url + str(i*10))
# loop through each job, breaking out if we're past the old jobs limit
for j in range(0, len(attrs_list)-1):
if old_jobs_counter >= old_jobs_limit:
break
href = attrs_list[j]['href']
title = attrs_list[j]['title']
company = attrs_list[j]['company']
date_posted = attrs_list[j]['date posted']
# if posting date is beyond the limit, add to the counter and skip
try:
if int(date_posted[0]) >= days_ago_limit:
print ('Adding to old_jobs_counter.')
old_jobs_counter += 1
continue
except:
pass
print ('{0}, {1}, {2}'.format(repr(company), repr(title), repr(date_posted)))
# evaluate the job
exploration = explore_job('http://indeed.co.uk' + href)
if exploration >= 1 or company.lower() in dream_companies:
new_jobs_list.append('{0}, {1}, {2}'.format(company, title, 'http://indeed.co.uk' + href))
print ('\n')
time.sleep(15)
new_jobs_string = '\n\n'.join(new_jobs_list)
return new_jobs_string
#links = get_new_ds_jobs('https://www.indeed.co.uk/jobs?q=machine+learning&l=United+Kingdom&sort=date')[:-1]
Sending the new jobs as email to myself
With the help of the smtplib library the email process is very easy. We will define a function that can send us email of our new jobs search for different scenerio.
def send_gmail(from_addr = 'your name <email address>', to_addr = 'email address',
location = 'United Kingdom',
subject = 'Daily Data Science and Machine Learning Jobs Update Scraped from Indeed', text = None):
message = 'Subject: {0}\n\nJobs in: {1}\n\n{2}'.format(subject, location, text)
# login information
username = '******'
password = '******'
# send the message
server = smtplib.SMTP('smtp.gmail.com:587')
server.ehlo()
server.starttls()
server.login(username, password)
server.sendmail(from_addr, to_addr, message)
server.quit()
print ('Email sent.')
Putting all the pieces Together
We want to make sure the code only runs when we execute the code as a stand-alone program, as opposed to if we import it into another program. The if name == “main” let’s me do just that.
def main():
print ('Scraping Indeed now.')
start_page = 0
page_limit = 2
location = 'United Kingdom'
machine_learning_jobs = get_new_ml_jobs(query = 'machine learning', starting_page = start_page,
location = location, pages_limit = page_limit, days_ago_limit = 1, old_jobs_limit = 5)
send_gmail(text = machine_learning_jobs, location = location)
data_scientist_jobs = get_new_ds_jobs(query = 'data scientist', starting_page = start_page,
location = location, pages_limit = page_limit, days_ago_limit = 1, old_jobs_limit = 5)
send_gmail(text = data_scientist_jobs, location = location)
if __name__ == "__main__":
main()
Scraping Indeed now.
URL: http://www.indeed.co.uk/jobs?q=machine+learning&l=United+Kingdom&sort=date&start=0
'Amazon', 'Data Scientist Analytics', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Dyson', 'Graduate Data Scientist 2018', 'Just posted'
ML count: 1, Python count: 0, DS count: 1, Research count: 2
'Amazon', 'Software Development Engineer', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Amazon', 'Knowledge Engineer (Alexa)', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Costello & Reyes Limited', 'Data Scientist', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Oliver Bernard', 'Data Scientist', 'Just posted'
ML count: 6, Python count: 2, DS count: 5, Research count: 2
'Time etc Limited', 'Onboarding Assistant', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
'University of Edinburgh', 'Research Assistant in Surgical Informatics', 'Just posted'
ML count: 0, Python count: 1, DS count: 5, Research count: 55
'InterQuest Group', 'Data Scientist', 'Just posted'
ML count: 4, Python count: 5, DS count: 4, Research count: 0
URL: http://www.indeed.co.uk/jobs?q=machine+learning&l=United+Kingdom&sort=date&start=10
'Caterpillar', 'Inventory Cycle Counter', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
'Square One Resources', 'Python Developer', 'Just posted'
ML count: 2, Python count: 14, DS count: 2, Research count: 0
'Kent Police and Essex Police', 'Contingency Planning Officer - OPC Boreham', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Quantcast', 'Software Engineering Intern - Summer 2018', 'Just posted'
ML count: 0, Python count: 1, DS count: 0, Research count: 0
'University of Edinburgh', 'Postdoctoral Research Associate in High Pressure Physics', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 44
'Hitachi Consulting UK Limited', 'Business Development Executive - Analytics', 'Just posted'
ML count: 4, Python count: 0, DS count: 2, Research count: 1
'Burden Bros', 'Skilled Groundworker', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
'NTT DATA Services', 'Enterprise Architect - Data / AI', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
'Burden Bros', 'Civil Working Foreman', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
Email sent.
URL: http://www.indeed.co.uk/jobs?q=data+scientist&l=United+Kingdom&sort=date&start=0
'Dyson', 'Graduate Data Scientist 2018', 'Just posted'
ML count: 1, Python count: 0, DS count: 1, Research count: 2
'Amazon', 'Data Scientist Analytics', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'HM Courts and Tribunals Service', 'Senior Performance Analyst and Data Scientist', 'Just posted'
ML count: 0, Python count: 0, DS count: 5, Research count: 5
'Oliver Bernard', 'Data Scientist', 'Just posted'
ML count: 6, Python count: 2, DS count: 5, Research count: 2
'Costello & Reyes Limited', 'Data Scientist', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Lancaster University', 'Research Associate in Nuclear Robotics Manipulator Control', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 7
'G-Research', 'Quantitative Operations Analyst', 'Just posted'
ML count: 3, Python count: 0, DS count: 0, Research count: 19
'InterQuest Group', 'Data Scientist', 'Just posted'
ML count: 4, Python count: 5, DS count: 4, Research count: 0
'University of Edinburgh', 'Research Assistant in Surgical Informatics', 'Just posted'
ML count: 0, Python count: 1, DS count: 5, Research count: 55
URL: http://www.indeed.co.uk/jobs?q=data+scientist&l=United+Kingdom&sort=date&start=10
'Lancaster University', 'Research Associate in Nuclear Robotics Control and Navigation', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 7
'IntaPeople', 'Data Engineer / Data Scientist', 'Just posted'
ML count: 0, Python count: 2, DS count: 2, Research count: 0
'GlaxoSmithKline', 'Category Medical Affairs Principal Scientist- Skin Health', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 3
'Amazon', 'Knowledge Engineer (Alexa)', 'Just posted'
'RZ Group', 'Quantitative Analyst', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 1
'SCI', 'Research Scientist, Antibody Discovery', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
'Talent Point', 'Senior Data Analyst', 'Just posted'
ML count: 0, Python count: 4, DS count: 6, Research count: 0
'Springer Nature', 'Associate Marketing Director, Journals', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 10
"J Sainsbury's", 'Senior Software Engineer - Android', 'Just posted'
ML count: 0, Python count: 0, DS count: 0, Research count: 0
Email sent.
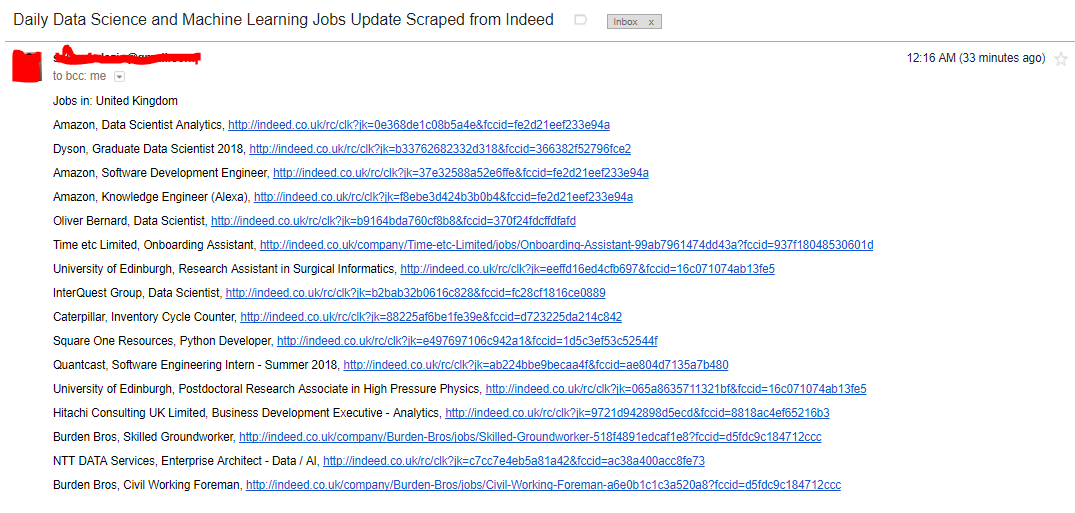
Here is the screenshot of the mail the scraping tool sent to me.
Conclusion
With the use of cron-job, we can set up our program to send us email every day with newly posted machine learning and data science jobs.
While this is particular useful, its about finding jobs that I might be a good fit for – not jobs that might be a good fit for me.
Leave a Comment